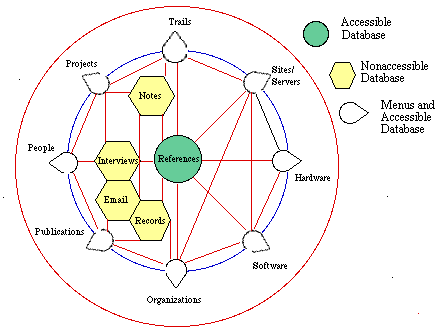
Database Structure and Access Used for Interpretation
|
Qualitative
Methodology |
Computation
Support Type and
Function |
Improvement
of Research in Terms of
Validity and Value |
|
Problem Definition |
On-line literature search and database for later
retrieval. |
Unusually broad, exhaustive and efficient review
and integration of relevant literature. |
|
Initial Research Design |
Database for efficient storage, retrieval and
analysis of data collected during the problem definition. |
Made multiple data sources reasonable, increasing number of participants,
situations and organizations. This
increased the validity through more breadth of perspective and extensive triangulation
opportunities. |
|
Data Collection |
Electronic notes by tape recorder and on-the-spot
word processing. |
Allowed for both more accurate and manageable
direct data capture during interviews and observation record after. |
|
Data Analysis and Emergent Design |
Extensive database with an easily editable and
re-definable coding scheme in hypertext. |
Because the data was immediately accessible in a
flexibly coded scheme, gradual evolving interpretations and knowledge
structures could be rapidly accommodated and used for reevaluation and
modification of the research design. Working definitions of key concepts were
coded, applied and redefined on the fly.
Flexible linking allowed early formulations to be easily tested, reformulated
and tested again with little cost to the researcher. Comparison groups were selected for
further specification and explanatory network re-developed more rapidly. |
|
Theory Construction |
Database allowing explicated hypertext links and
multiple simultaneous linking schemes. |
The use of hypertext in the analysis allowed the
ability to document and trace complex relationships. In addition, multiple schemes could
simultaneously be implemented to allow comparisons between competing
interpretations. Complex propositions
were developed and validated with numerous relatively rapid passes/searches
of data. |
|
Reporting Findings |
Hypermedia representations were constructed and
presented. |
Allowed a non-linear presentation of the results
that more accurately represented the findings during presentations. |
|
Contributions to Knowledge and Further Research |
A continually expandable database was established. |
Captured and preserved extensive new longitudinal
documentation of historically significant projects in a database that can be
contributed to by both the original researcher and others. This can be distributed cheaply as a
community resource for research and instruction. Depth of data easily
communicated to other researchers for analysis. Constructed mapping of relationships to be further tested in both
quantitative and qualitative works. |
[See 2.2 Research Plan.]
The investigator started with a tentative design and developed the design
further as the inquiry progressed (Borg & Gall, 1989).
Preliminary research questions were formulated to guide the researchers activities,
rather than a traditional set of research hypotheses like those used in quantitative
research. The questions were focused on the three major contexts inherent in the
nature of "educational computing projects". The following questions were
the foundation of this study:
General Question
What were the relationships between the educational, technical, and
organizational contexts of courseware?
Educational Questions
What were the educational goals of the courseware?
Did the goals focus more upon discipline oriented outcomes,
or upon broader outcomes for the learners?
Technical Questions
What educational considerations influenced technical decisions about courseware?
What were pragmatic technical issues that emerged during courseware projects?
What were key technical characteristics that determined the viability of courseware?
Organizational Questions
What were the relationships between the roles, tasks, and the timing of tasks?
What were implicit or explicit educational, technical, financial,
and personnel support policies within the organization(s) which had
an impact on courseware projects?
[See 2.1 Research Questions.]
Projects and Participants
Participants in this study were key developers and managers in educational
computing initiatives or courseware development projects that used networked
workstations from more than one vendor. Participants from four different
organizations were selected to allow distinctions to be made between phenomena
common across institutions and phenomena that occurred due to circumstances
in particular organizations.
|
The following projects, organizations and participants were the focus of this study:
Project: ESCAPE (HyperCard and HyperNews) Organizations: Educational Research and Information Systems (ERIS, Purdue) Participants: Hopper, Lawler, LeBold, Putnam, Rehwinkel, Tillotson, Ward Project: TODOR (BLOX) & Mechanics 2.01 (cT, Athena) Organizations: Athena and Academic Computing (AC, MIT) Participants: Bucciarelli, Daly, Jackson, Lavin, Schmidt Project: Physical Geology Tutor (AthenaMuse) Organizations: Center for Educational Computing Initiatives (CECI, MIT) Participants: Davis, Kinnicutt, Lerman, Schlusselberg Project: Context32 (Intermedia, StorySpace) Organizations: Institute for Research and Information Scholarship (IRIS, Brown) Participants: Kahn, Landow, Yankelovich [See the Switchboard for further information.] |
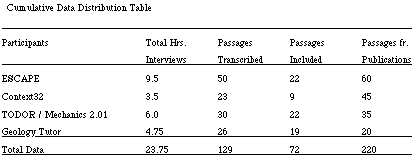
Table: Cummlative Distribution of Data Collection
[See 2.5 Data Collection.]
Data Analysis
Databases of vignettes from interviews and publications were developed
to store and analyze data. The researcher added working notes that helped
guide the ongoing data collection and analysis process. These notes became
more systematic as increasing numbers of vignettes were collected and analyzed.
After all interviews were complete, the working notes were refined into a
catalog of key themes cross-referenced to the database of vignettes.
The researcher used this system to analyze the relationships between
recurring issues discussed by different participants in different settings.
The final product of this process was a model describing the relationships
between educational goals, technical characteristics, and organizational
structures of advanced educational courseware projects. The explanations
provided by participants from their "expert" perspectives provided the basis
for "grounded theory" about key factors in the successful and unsuccessful
operation of these projects in advanced environments
(Marshall and Rossman, 1989).
[See 2.6 Data Analysis.]
Database Structure and Access Used for Interpretation
[See Chapter 2 Methodology.]